四、人工智能拥抱大数据
4.1 机器什么时候才能懂人心
虽说有了大数据,人的欲望总是这个不能够满足。虽说在大数据平台里面有搜索引擎这个东西,想要什么东西我一搜就出来了。但是也存在这样的情况,我想要的东西不会搜,表达不出来,搜索出来的又不是我想要的。例如音乐软件里面推荐一首歌,这首歌我没听过,当然不知道名字,也没法搜,但是软件推荐给我,我的确喜欢,这就是搜索做不到的事情。当人们使用这种应用的时候,会发现机器知道我想要什么,而不是说当我想要的时候,去机器里面搜索。这个机器真像我的朋友一样懂我,这就有点人工智能的意思了。
人们很早就在想这个事情了。最早的时候,人们想象,如果要是有一堵墙,墙后面是个机器,我给它说话,它就给我回应,我如果感觉不出它那边是人还是机器,那它就真的是一个人工智能的东西了。
4.2 让机器学会推理
怎么才能做到这一点呢?人们就想:我首先要告诉计算机人类的推理的能力。你看人重要的是什么呀,人和动物的区别在什么呀,就是能推理。我要是把我这个推理的能力啊告诉机器,机器就能根据你的提问,推理出相应的回答,真能这样多好。推理其实人们慢慢的让机器能够做到一些了,例如证明数学公式。这是一个非常让人惊喜的一个过程,机器竟然能够证明数学公式。但是慢慢发现其实这个结果,也没有那么令人惊喜,因为大家发现了一个问题,数学公式非常严谨,推理过程也非常严谨,而且数学公式很容易拿机器来进行表达,程序也相对容易表达。然而人类的语言就没这么简单了,比如今天晚上,你和你女朋友约会,你女朋友说:如果你早来,我没来,你等着,如果我早来,你没来,你等着。这个机器就比比较难理解了,但是人都懂,所以你和女朋友约会,你是不敢迟到的。
4.3 教给机器知识
所以仅仅告诉机器严格的推理是不够的,还要告诉机器一些知识。但是知识这个事儿,一般人可能就做不来了,可能专家可以,比如语言领域的专家,或者财经领域的专家。语言领域和财经领域知识能不能表示成像数学公式一样稍微严格点呢?例如语言专家可能会总结出主谓宾定状补这些语法规则,主语后面一定是谓语,谓语后面一定是宾语,将这些总结出来,并严格表达出来不就行了吗?后来发现这个不行,太难总结了,语言表达千变万化。就拿主谓宾的例子,很多时候在口语里面就省略了谓语,别人问:你谁啊?我回答:我刘超。但是你不能规定在语音语义识别的时候,要求对着机器说标准的书面语,这样还是不够智能,就像罗永浩在一次演讲中说的那样,每次对着手机,用书面语说:请帮我呼叫某某某,这是一件很尴尬的事情。
人工智能这个阶段叫做专家系统。专家系统不易成功,一方面是知识比较难总结,另一方面总结出来的知识难以教给计算机。因为你自己还迷迷糊糊,似乎觉得有规律,就是说不出来,就怎么能够通过编程教给计算机呢?
4.4 算了,教不会你自己学吧
于是人们想到,看来机器是和人完全不一样的物种,干脆让机器自己学习好了。机器怎么学习呢?既然机器的统计能力这么强,基于统计学习,一定能从大量的数字中发现一定的规律。
其实在娱乐圈有很好的一个例子,可见一斑
有一位网友统计了知名歌手在大陆发行的 9 张专辑中 117 首歌曲的歌词,同一词语在一首歌出现只算一次,形容词、名词和动词的前十名如下表所示(词语后面的数字是出现的次数):
|
a
|
形容词
|
b
|
名词
|
c
|
动词
|
|
0
|
孤独:34
|
0
|
生命:50
|
0
|
爱:54
|
|
1
|
自由:17
|
1
|
路:37
|
1
|
碎:37
|
|
2
|
迷惘:16
|
2
|
夜:29
|
2
|
哭:35
|
|
3
|
坚强:13
|
3
|
天空:24
|
3
|
死:27
|
|
4
|
绝望:8
|
4
|
孩子:23
|
4
|
飞:26
|
|
5
|
青春:7
|
5
|
雨:21
|
5
|
梦想:14
|
|
6
|
迷茫:6
|
6
|
石头:9
|
6
|
祈祷:10
|
|
7
|
光明:6
|
7
|
鸟:9
|
7
|
离去:10
|
如果我们随便写一串数字,然后按照数位依次在形容词、名词和动词中取出一个词,连在一起会怎么样呢?
例如取圆周率 3.1415926,对应的词语是:坚强,路,飞,自由,雨,埋,迷惘。稍微连接和润色一下:
坚强的孩子,
依然前行在路上,
张开翅膀飞向自由,
让雨水埋葬他的迷惘。
是不是有点感觉了?当然真正基于统计的学习算法比这个简单的统计复杂的多。
然而统计学习比较容易理解简单的相关性,例如一个词和另一个词总是一起出现,两个词应该有关系,而无法表达复杂的相关性,并且统计方法的公式往往非常复杂,为了简化计算,常常做出各种独立性的假设,来降低公式的计算难度,然而现实生活中,具有独立性的事件是相对较少的。
4.5 模拟大脑的工作方式
于是人类开始从机器的世界,反思人类的世界是怎么工作的。
人类的脑子里面不是存储着大量的规则,也不是记录着大量的统计数据,而是通过神经元的触发实现的,每个神经元有从其他神经元的输入,当接收到输入的时候,会产生一个输出来刺激其他的神经元,于是大量的神经元相互反应,最终形成各种输出的结果。例如当人们看到美女瞳孔放大,绝不是大脑根据身材比例进行规则判断,也不是将人生中看过的所有的美女都统计一遍,而是神经元从视网膜触发到大脑再回到瞳孔。在这个过程中,其实很难总结出每个神经元对最终的结果起到了哪些作用,反正就是起作用了。
于是人们开始用一个数学单元模拟神经元
这个神经元有输入,有输出,输入和输出之间通过一个公式来表示,输入根据重要程度不同(权重),影响着输出。
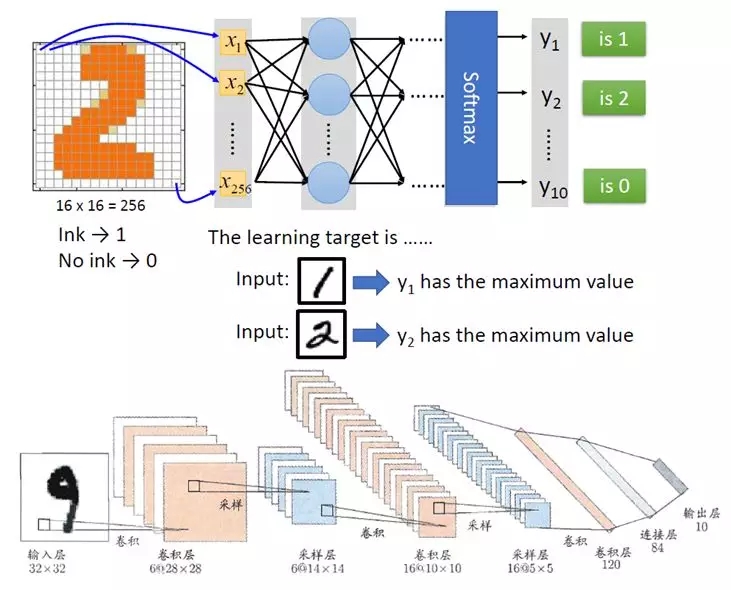
于是将n个神经元通过像一张神经网络一样连接在一起,n这个数字可以很大很大,所有的神经元可以分成很多列,每一列很多个排列起来,每个神经元的对于输入的权重可以都不相同,从而每个神经元的公式也不相同。当人们从这张网络中输入一个东西的时候,希望输出一个对人类来讲正确的结果。例如上面的例子,输入一个写着2的图片,输出的列表里面第二个数字最大,其实从机器来讲,它既不知道输入的这个图片写的是2,也不知道输出的这一系列数字的意义,没关系,人知道意义就可以了。正如对于神经元来说,他们既不知道视网膜看到的是美女,也不知道瞳孔放大是为了看的清楚,反正看到美女,瞳孔放大了,就可以了。
对于任何一张神经网络,谁也不敢保证输入是2,输出一定是第二个数字最大,要保证这个结果,需要训练和学习。毕竟看到美女而瞳孔放大也是人类很多年进化的结果。学习的过程就是,输入大量的图片,如果结果不是想要的结果,则进行调整。如何调整呢,就是每个神经元的每个权重都向目标进行微调,由于神经元和权重实在是太多了,所以整张网络产生的结果很难表现出非此即彼的结果,而是向着结果微微的进步,最终能够达到目标结果。当然这些调整的策略还是非常有技巧的,需要算法的高手来仔细的调整。正如人类见到美女,瞳孔一开始没有放大到能看清楚,于是美女跟别人跑了,下次学习的结果是瞳孔放大一点点,而不是放大鼻孔。
4.6 没道理但做得到
听起来也没有那么有道理,但是的确能做到,就是这么任性。
神经网络的普遍性定理是这样说的,假设某个人给你某种复杂奇特的函数,f(x):
不管这个函数是什么样的,总会确保有个神经网络能够对任何可能的输入x,其值f(x)(或者某个能够准确的近似)是神经网络的输出。
如果在函数代表着规律,也意味着这个规律无论多么奇妙,多么不能理解,都是能通过大量的神经元,通过大量权重的调整,表示出来的。
4.7 人工智能的经济学解释
这让我想到了经济学,于是比较容易理解了。
我们把每个神经元当成社会中从事经济活动的个体。于是神经网络相当于整个经济社会,每个神经元对于社会的输入,都有权重的调整,做出相应的输出,比如工资涨了,菜价也涨了,股票跌了,我应该怎么办,怎么花自己的钱。这里面没有规律么?肯定有,但是具体什么规律呢?却很难说清楚。
基于专家系统的经济属于计划经济,整个经济规律的表示不希望通过每个经济个体的独立决策表现出来,而是希望通过专家的高屋建瓴和远见卓识总结出来。专家永远不可能知道哪个城市的哪个街道缺少一个卖甜豆腐脑的。于是专家说应该产多少钢铁,产多少馒头,往往距离人民生活的真正需求有较大的差距,就算整个计划书写个几百页,也无法表达隐藏在人民生活中的小规律。
基于统计的宏观调控就靠谱的多了,每年统计局都会统计整个社会的就业率,通胀率,GDP等等指标,这些指标往往代表着很多的内在规律,虽然不能够精确表达,但是相对靠谱。然而基于统计的规律总结表达相对比较粗糙,比如经济学家看到这些统计数据可以总结出长期来看房价是涨还是跌,股票长期来看是涨还是跌,如果经济总体上扬,房价和股票应该都是涨的。但是基于统计数据,无法总结出股票,物价的微小波动规律。
基于神经网络的微观经济学才是对整个经济规律最最准确的表达,每个人对于从社会中的输入,进行各自的调整,并且调整同样会作为输入反馈到社会中。想象一下股市行情细微的波动曲线,正是每个独立的个体各自不断交易的结果,没有统一的规律可循。而每个人根据整个社会的输入进行独立决策,当某些因素经过多次训练,也会形成宏观上的统计性的规律,这也就是宏观经济学所能看到的。例如每次货币大量发行,最后房价都会上涨,多次训练后,人们也就都学会了。
4.8 人工智能需要大数据
然而神经网络包含这么多的节点,每个节点包含非常多的参数,整个参数量实在是太大了,需要的计算量实在太大,但是没有关系啊,我们有大数据平台,可以汇聚多台机器的力量一起来计算,才能在有限的时间内得到想要的结果。
人工智能可以做的事情非常多,例如可以鉴别垃圾邮件,鉴别黄色暴力文字和图片等。这也是经历了三个阶段的。第一个阶段依赖于关键词黑白名单和过滤技术,包含哪些词就是黄色或者暴力的文字。随着这个网络语言越来越多,词也不断的变化,不断的更新这个词库就有点顾不过来。第二个阶段时,基于一些新的算法,比如说贝叶斯过滤等,你不用管贝叶斯算法是什么,但是这个名字你应该听过,这是一个基于概率的算法。第三个阶段就是基于大数据和人工智能,进行更加精准的用户画像和文本理解和图像理解。
由于人工智能算法多是依赖于大量的数据的,这些数据往往需要面向某个特定的领域(例如电商,邮箱)进行长期的积累,如果没有数据,就算有人工智能算法也白搭,所以人工智能程序很少像前面的IaaS和PaaS一样,将人工智能程序给某个客户安装一套让客户去用,因为给某个客户单独安装一套,客户没有相关的数据做训练,结果往往是很差的。但是云计算厂商往往是积累了大量数据的,于是就在云计算厂商里面安装一套,暴露一个服务接口,比如您想鉴别一个文本是不是涉及黄色和暴力,直接用这个在线服务就可以了。这种形势的服务,在云计算里面称为软件即服务,SaaS (Software AS A Service)
于是工智能程序作为SaaS平台进入了云计算。
五、云计算,大数据,人工智能过上了美好的生活
终于云计算的三兄弟凑齐了,分别是IaaS,PaaS和SaaS,所以一般在一个云计算平台上,云,大数据,人工智能都能找得到。对一个大数据公司,积累了大量的数据,也会使用一些人工智能的算法提供一些服务。对于一个人工智能公司,也不可能没有大数据平台支撑。所以云计算,大数据,人工智能就这样整合起来,完成了相遇,相识,相知。
(本文转载于刘超的通俗云计算,作者刘超)
(全文完)